

In the context of digital transformation and artificial intelligence (AI) transformation in Vietnam, OCR technology (optical character recognition) plays an increasingly important role in digitizing documents, automating business processes, saving costs and improving management efficiency. However, with the characteristics of Vietnamese with accents and handwriting, the recognition problem does not stop at 'reading words', but requires the model to have the ability to understand the context comprehensively.
Recently, CMC Technology Application Institute (CMC ATI) announced the CATI-VLM (Visual Document Understanding) model developed by the research team from a 5TB large data warehouse, reaching Top 12 in the world and Top 1 in Vietnam in the rankings just announced by Robust Reading Competition (RRC) in June 2025 in the Document Visual Question Answering (DocVQA) category.
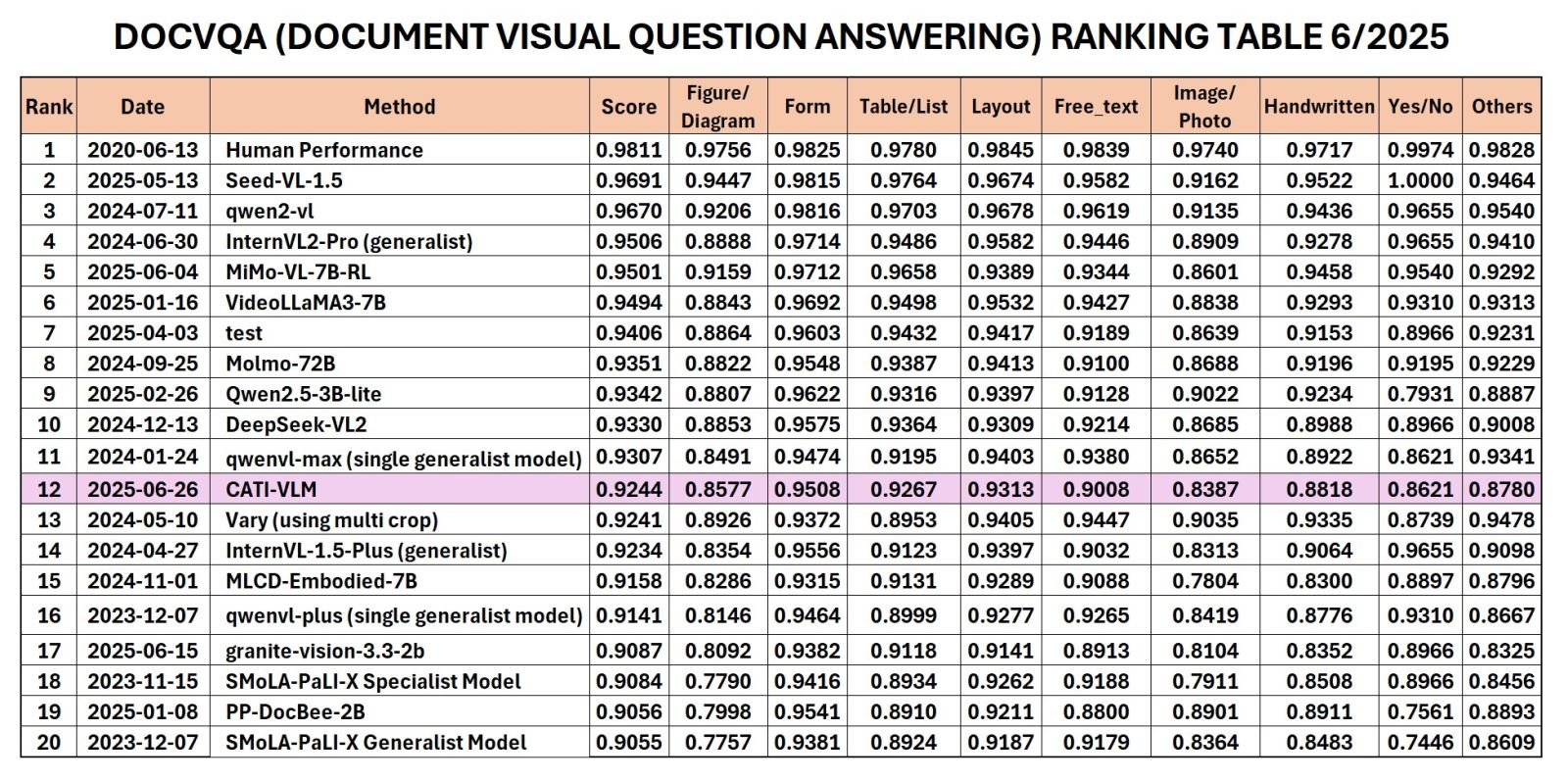
RRC ranking in DocVQA category 6/2025.
Robust Reading Competition (RRC) is a prestigious scientific playground, (https://rrc.cvc.uab.es/) organized by the Computer Vision Center (CVC) of the Universitat Autònoma de Barcelona (UAB) Spain, a prestigious research facility in the world in the field of computer vision. Initiated in 2011, always accompanying the International Conference on Text Analysis and Recognition ICDAR - one of the world's largest forums on document analysis and computer vision, the competition has become an important event, attracting researchers, engineers from prestigious universities, research institutes and technology companies such as Tsinghua University, Hyundai Motor Group, and Tencent... RRC's tasks are designed to promote technological progress, closely linked to practical problems from translation, enterprise data management to urban analysis and historical document processing.
Dr. Dang Minh Tuan, Director of CMC ATI, shared: "The research capacity of the CMC team is affirmed through a prestigious global playground like RRC. We are proud that in just a short time, the team can achieve a high ranking, standing shoulder to shoulder with big names from developed countries. More importantly, this is a clear demonstration of the ability to master technology to solve specific problems of Vietnamese and specialized fields in Vietnam."
CATI-VLM differs from traditional OCR in that it not only extracts characters, but also understands multiple layers of information: text content, non-text elements (tick boxes, checkboxes, charts, signatures, formulas), layout (page structure, tables, forms) and style (fonts, highlights, etc.). The model can answer visual questions posed on document images, similar to ChatGPT, without having to learn specific forms in advance.
According to News and People Newspaper
Source: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051

![[Photo] Multi-colored cultural space at the Exhibition "80 years of the journey of Independence - Freedom - Happiness"](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/8/26/fe69de34803e4ac1bf88ce49813d95d8)

![[Photo] Hanoi: Authorities work hard to overcome the effects of heavy rain](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/8/26/380f98ee36a34e62a9b7894b020112a8)































































































Comment (0)