
사용자 생애 가치(LTV)는 앱 수익의 효과를 측정하는 중요한 지표입니다. LTV를 정확하게 측정하려면 많은 인적, 물적 자원이 필요하며, AI의 발전 덕분에 이 과정이 더욱 쉬워졌습니다.

세계 최고의 광고 네트워크 중 하나인 Yandex Ads의 앱 캠페인 제품 책임자인 Anton Ogay 씨는 생애 가치(LTV)의 잠재력에 대해 다음과 같이 설명합니다.

PV: 앱 개발자가 글로벌 경쟁에서 이기는 데 있어 생애 가치(LTV)는 어떤 역할을 하나요?
안톤 오게이: LTV 데이터를 통해 개발자는 사용자가 가져올 수 있는 가치와 사용자 확보 비용을 파악하여 앱 내 구매 및 앱 내 광고와 같은 수익원을 최적화할 수 있습니다. 따라서 LTV는 사용자가 앱에 창출하는 가치를 파악하는 데 도움이 되며, 개발자는 사용자 기반에 집중하여 원하는 사용자 기반을 타겟팅하는 효과적인 마케팅 활동을 제안함으로써 앱 판매를 최적화할 수 있는 최고의 가치를 창출할 수 있습니다. LTV는 앱 다운로드 수, 앱 사용 시간 등과 같은 표면적인 지표를 넘어, 전 세계 사용자 행동 및 선호도에 대한 인사이트를 제공하며, 개발자가 장기적인 성공을 위한 효과적인 캠페인을 시작할 수 있는 기반이 됩니다.
LTV는 어떻게 측정하나요? 모바일 게임 퍼블리셔들이 앱의 LTV 측정에 실패할 때 어떤 어려움을 겪나요?
LTV는 평균 매출, 구매 빈도, 이익률, 고객 충성도 등 다양한 요소를 고려하여 시간 경과에 따라 고객이 창출하는 총 수익을 파악하는 과정입니다. 따라서 개발자는 부정확하거나 불완전할 수 있는 방대한 양의 데이터를 관리해야 하는 어려움에 직면하게 되며, 이는 사용자 행동과 수익 창출에 대한 정확한 인사이트를 얻는 데 방해가 됩니다. 최적의 측정을 위해서는 게임 개발자에게 방대한 양의 사용자 데이터가 필요하지만, 이는 특히 이를 감당할 여력이 없는 중소 규모 개발사에게는 어려운 과제가 될 수 있습니다. 이는 앱 개발자의 부담을 가중시킵니다. 더욱이 AI의 등장으로 LTV 측정의 정확도가 높아져 개발자는 사용자 행동을 더욱 깊이 이해하고 마케팅 전략을 효과적으로 최적화할 수 있습니다.
그렇다면 LTV를 측정하기 위해 AI를 어떻게 적용할까요?
AI 기반 모델은 앱 사용, 사용자 행동, 시장 동향 등 다양한 출처의 데이터를 분석하여 개별 사용자 또는 그룹의 향후 LTV를 예측할 수 있습니다. 이러한 모델은 인간이 즉시 파악하기 어려운 미래 동향을 파악하여 사용자 가치에 대한 더욱 정확하고 포괄적인 인사이트를 제공합니다. 예를 들어 AppMetrica 앱 분석 플랫폼에는 Yandex Ads의 머신러닝 기술을 기반으로 다양한 카테고리에 걸쳐 수만 개의 앱에서 익명화된 데이터를 사용하는 예측 LTV 모델이 통합되었습니다. 이를 통해 앱 팀은 앱 자체의 데이터 없이도 정확한 수익 창출 예측을 수행할 수 있습니다. 앱 설치 후 24시간 이내에 모델은 여러 LTV 관련 지표를 분석하고 앱 수익 창출 능력에 따라 사용자를 그룹으로 분류합니다. LTV가 가장 높은 상위 5% 사용자부터 상위 20% 또는 상위 50% 사용자까지 그룹으로 나눕니다.
LTV 측정 및 예측에 AI를 성공적으로 적용한 사례가 있나요?
앞서 언급했듯이 소규모 개발사는 LTV 계산 및 예측에 필요한 데이터에 접근하는 데 어려움을 겪는 경우가 많습니다. 이 문제를 해결하기 위해 저희는 프로세스를 자동화하고 Yandex의 자체 광고주 플랫폼인 Yandex Direct에서 데이터를 마이닝했습니다. Yandex Direct는 수만 개의 앱과 수억 명의 사용자 파일을 기반으로 하는 방대한 데이터 풀을 보유하고 있습니다. 이러한 모델을 통해 광고주는 모바일 앱을 홍보하여 설치 후 전환율을 높이고 수익을 증대할 수 있으며, 특히 설치당 지불(Pay Per Install) 캠페인에서 효과적입니다. Yandex Direct에서 데이터가 수집되면 AppMetrica의 알고리즘이 사용자 LTV를 예측하는 점수를 계산하기 시작합니다. 저희는 이 점수를 사용하여 모델을 학습시키고 설치 후 목표 행동의 확률을 예측에 반영합니다. 시스템은 이 점수를 기반으로 광고 전략을 자동으로 조정합니다.
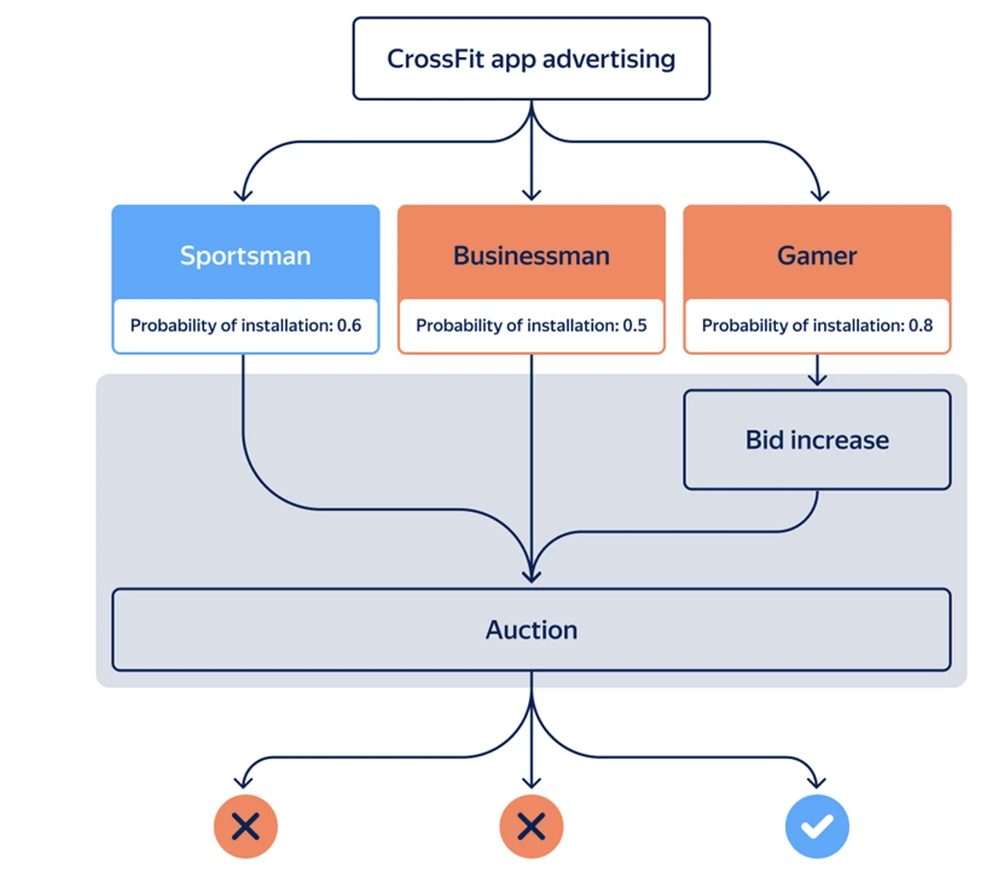
이 모델은 데이터를 축적함으로써 특정 애플리케이션에서 객체의 동작을 학습하고 적응하여 예측 정확도를 99%까지 높입니다. 이러한 예측의 신뢰성은 저희가 분석하는 방대하고 다양한 익명화된 데이터에서 비롯되며, 이를 통해 사람이 즉시 알아차리기 어려운 패턴과 추세를 파악할 수 있습니다. 이 데이터는 사용자 가치에 대한 정확하고 포괄적인 인사이트를 제공하는 예측 모델을 구축하는 데 사용됩니다.
빈 램
[광고_2]
원천






























































































댓글 (0)