

В контексте цифровой трансформации и развития искусственного интеллекта (ИИ) во Вьетнаме технология OCR (оптического распознавания символов) играет всё более важную роль в оцифровке документов, автоматизации бизнес-процессов, сокращении затрат и повышении эффективности управления. Однако, учитывая особенности вьетнамского языка, включая акцент и почерк, проблема распознавания не ограничивается «чтением слов», а требует от модели способности всесторонне понимать контекст.
Недавно Институт применения технологий CMC (CMC ATI) объявил о том, что модель CATI-VLM (визуальное понимание документов), разработанная исследовательской группой на основе хранилища данных объемом 5 ТБ, вошла в топ-12 в мире и топ-1 во Вьетнаме в рейтинге, недавно объявленном Robust Reading Competition (RRC) в июне 2025 года в категории «Визуальные вопросы и ответы по документам» (DocVQA).
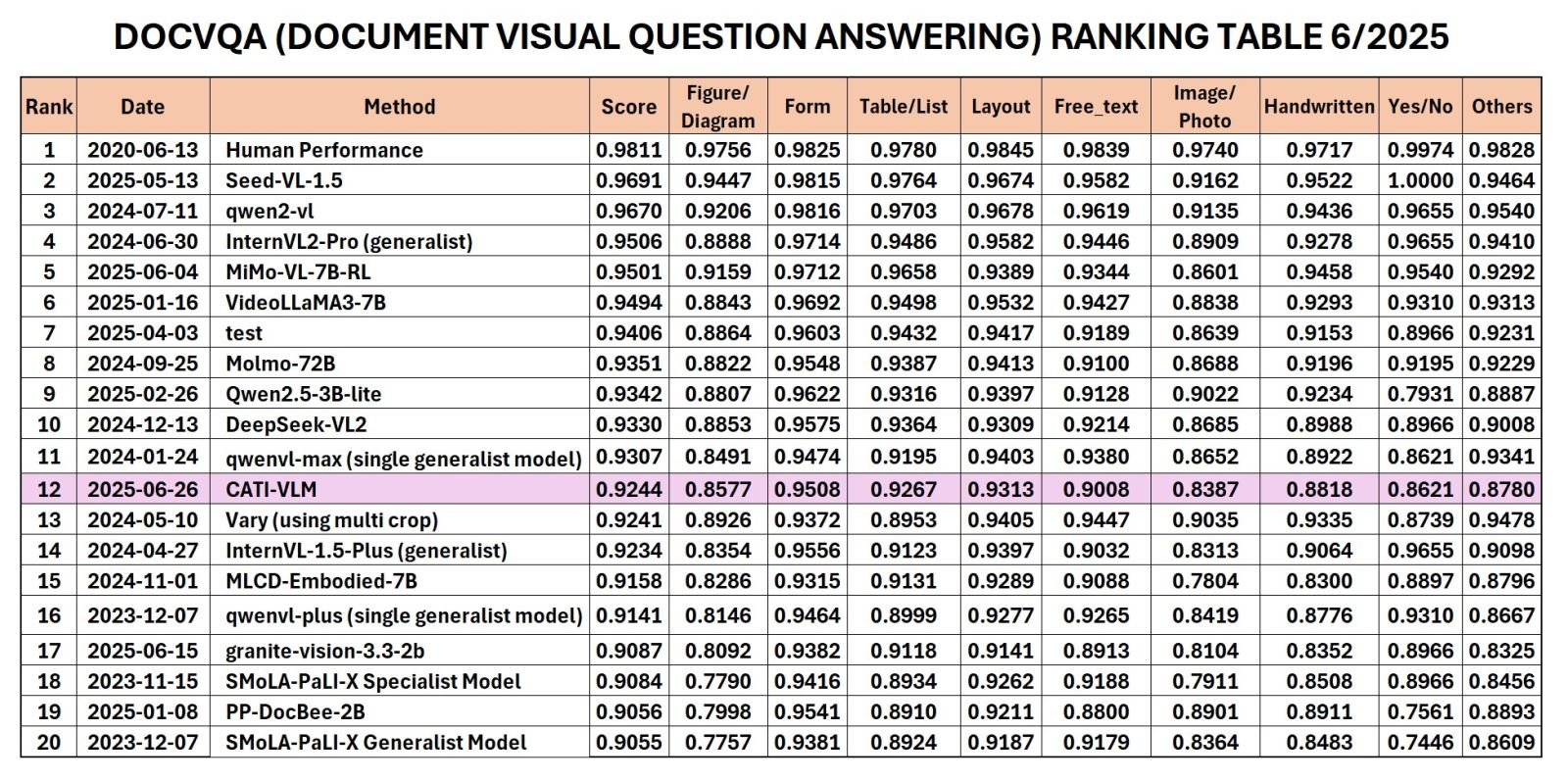
Рейтинг RRC в категории DocVQA 6/2025.
Конкурс Robust Reading Competition (RRC) – престижная научная площадка (https://rrc.cvc.uab.es/), организованная Центром компьютерного зрения (CVC) Автономного университета Барселоны (UAB), Испания, авторитетным исследовательским центром в мире в области компьютерного зрения. Запущенный в 2011 году и неизменно сопровождающий Международную конференцию по анализу и распознаванию текста (ICDAR) – один из крупнейших в мире форумов по анализу документов и компьютерному зрению, конкурс стал важным событием, привлекающим исследователей, инженеров из престижных университетов, исследовательских институтов и технологических компаний, таких как Университет Цинхуа, Hyundai Motor Group и Tencent... Задачи RRC направлены на содействие технологическому прогрессу, тесно связанному с практическими задачами – от перевода и управления корпоративными данными до анализа городской среды и обработки исторических документов.
Доктор Данг Минь Туан, директор CMC ATI, отметил: «Исследовательский потенциал команды CMC подтверждается такой престижной международной площадкой, как RRC. Мы гордимся тем, что за столь короткое время команда смогла достичь высокого рейтинга, встав плечом к плечу с известными именами из развитых стран. Что ещё важнее, это наглядно демонстрирует способность осваивать технологии для решения специфических проблем вьетнамской науки и специализированных областей во Вьетнаме».
CATI-VLM отличается от традиционного OCR тем, что не только извлекает символы, но и распознаёт несколько слоёв информации: текстовое содержимое, нетекстовые элементы (флажки, чекбоксы, диаграммы, подписи, формулы), макет (структуру страницы, таблицы, формы) и стиль (шрифты, выделение и т. д.). Модель может отвечать на визуальные вопросы, заданные на изображениях документов, подобно ChatGPT, без необходимости предварительного изучения конкретных форм.
По данным газеты News and People
Источник: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051
![[Фото] Премьер-министр Фам Минь Чинь председательствует на заседании Национального руководящего комитета по международной интеграции](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/8/26/9d34a506f9fb42ac90a48179fc89abb3)

![[Фото] Премьер-министр Фам Минь Чинь встречает генерального директора Samsung Electronics](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/8/26/373f5db99f704e6eb1321c787485c3c2)
![[Фото] Разноцветное культурное пространство на выставке «80 лет пути Независимости – Свободы – Счастья»](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/8/26/fe69de34803e4ac1bf88ce49813d95d8)





























































































Комментарий (0)