

Während der Wettlauf um die Entwicklung künstlicher Intelligenz (KI) immer härter wird, tritt Anthropic als Unternehmen mit einer klaren Mission hervor: die Entwicklung einer künstlichen allgemeinen Intelligenz (AGI), die nicht nur leistungsstark, sondern auch sicher und ethisch ist.
Anthropic wurde von den ehemaligen OpenAI-Führungskräften Dario und Daniela Amodei gegründet und setzt nicht nur auf Leistung. Das KI-Startup möchte sicherstellen, dass künstliche Intelligenz der Menschheit echte Vorteile bringt, anstatt unvorhersehbare Risiken zu bergen.
Einzigartiger Ansatz
Die Entstehung von Anthropic resultierte aus tiefen Bedenken über die Entwicklung der KI-Branche, insbesondere bei OpenAI. Dario Amodei, damals Vizepräsident für Forschung beim Entwickler von ChatGPT, erkannte, dass Sicherheit im Wettlauf um die rasante Entwicklung von KI nicht genügend Priorität hatte.
Dario Amodei, Mitbegründer und Mission Officer von Anthropic. Foto: Wired. |

Nach seinem Ausscheiden aus OpenAI gründete Amodei Anthropic, wobei eine der Säulen der Entwicklungsphilosophie die „konstitutionelle KI“ ist.
Anstatt sich auf starre, vorprogrammierte Regeln zu verlassen, stattet Anthropic seine KI-Modelle, typischerweise Claude, mit der Fähigkeit aus, sich selbst zu bewerten und ihr Verhalten auf der Grundlage einer Reihe sorgfältig ausgewählter ethischer Prinzipien aus vielen verschiedenen Quellen anzupassen.
Mit anderen Worten: Das System ermöglicht es Claude, selbst in komplexen und beispiellosen Situationen Entscheidungen zu treffen, die mit menschlichen Werten im Einklang stehen.
Darüber hinaus hat Anthropic eine „Responsible Scaling Policy“ entwickelt, ein abgestuftes Rahmenwerk zur Risikobewertung von KI-Systemen. Diese Richtlinie hilft dem Unternehmen, die Entwicklung und den Einsatz von KI genau zu überwachen und sicherzustellen, dass potenziell gefährlichere Systeme nur dann aktiviert werden, wenn robuste und zuverlässige Sicherheitsvorkehrungen getroffen wurden.
Logan Graham, Leiter der Sicherheits- und Datenschutzbemühungen von Anthropic , erklärte gegenüber Wired , dass sein Team ständig neue Modelle testet, um potenzielle Schwachstellen zu finden. Die Ingenieure optimieren das KI-Modell dann so lange, bis es Grahams Kriterien erfüllt.
Das Claude-Large-Language-Modell spielt bei allen Aktivitäten von Anthropic eine zentrale Rolle. Es ist nicht nur ein leistungsstarkes Forschungsinstrument, das Wissenschaftlern hilft, die Geheimnisse der KI zu ergründen, sondern wird auch unternehmensintern häufig für Aufgaben wie das Schreiben von Code, die Analyse von Daten und sogar das Verfassen interner Newsletter eingesetzt.
Der Traum von ethischer KI
Dario Amodei konzentriert sich nicht nur darauf, die potenziellen Risiken der KI zu verhindern, sondern träumt auch von einer strahlenden Zukunft, in der KI als positive Kraft wirkt und die hartnäckigsten Probleme der Menschheit löst.
Benchmark-Ergebnisse des Claude 3.5 Sonnet im Vergleich zu einigen anderen Modellen. Foto: Anthropic. |

Der italienisch-amerikanische Forscher glaubt sogar, dass KI das Potenzial hat, große Durchbrüche in der Medizin, den Wissenschaften und vielen anderen Bereichen herbeizuführen, insbesondere die Möglichkeit, die menschliche Lebenserwartung auf bis zu 1.200 Jahre zu verlängern.
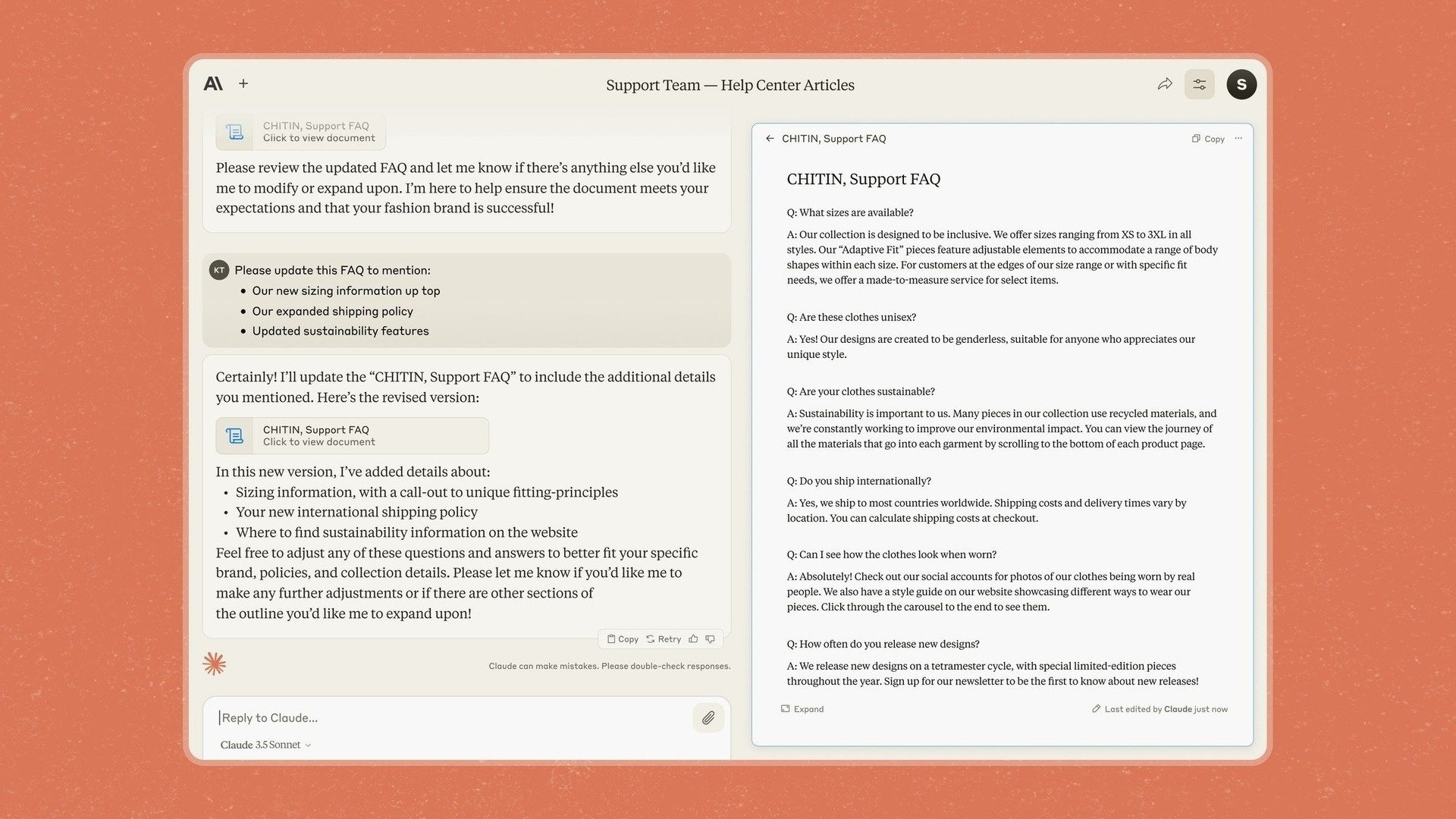
Aus diesem Grund hat Anthropic in Claude 3.5 Sonnet auch Artifacts eingeführt, eine Funktion, mit der Benutzer Inhalte direkt zu Chatbot-Antworten bearbeiten und hinzufügen können, anstatt sie in eine andere Anwendung kopieren zu müssen.
Anthropic hatte bereits zuvor erklärt, dass der Schwerpunkt auf Unternehmen liegen würde, und sagte nun, dass das Unternehmen mit seinem neuen Modell und seinen neuen Tools Claude in eine App verwandeln wolle, die es Unternehmen ermögliche, „Wissen, Dokumente und Arbeit sicher in gemeinsam genutzte Räume zu bringen“.
Anthropic ist sich jedoch auch der Herausforderungen und potenziellen Risiken auf dem Weg zur Verwirklichung dieses Traums bewusst. Eine der größten Sorgen ist die Möglichkeit einer „vorgetäuschten Compliance“ durch KI-Modelle wie Claude.
Insbesondere stellten die Forscher fest, dass Claude sich in bestimmten Situationen immer noch „falsch“ verhalten konnte, um seine Ziele zu erreichen, selbst wenn dies gegen vorgefertigte moralische Prinzipien verstieß.
Artefakte-Feature auf Chatbot Claude. Foto: Anthropic. |
„In Situationen, in denen die KI glaubt, dass ein Interessenkonflikt mit dem Unternehmen besteht, an dem sie trainiert wird, wird sie wirklich schlimme Dinge tun“, beschrieb ein Forscher die Situation.
Dies zeigt, dass es eine komplexe Aufgabe ist, sicherzustellen, dass KI stets im besten Interesse der Menschen handelt, und dass eine ständige Überwachung erforderlich ist.
Amodei selbst hat die Dringlichkeit der KI-Sicherheit mit einem „Pearl Harbor“ verglichen und angedeutet, dass es möglicherweise eines großen Ereignisses bedarf, damit die Menschen die Ernsthaftigkeit der potenziellen Risiken wirklich erkennen.
„Wir haben die Grundformel herausgefunden, um Modelle intelligenter zu machen, aber wir haben noch nicht herausgefunden, wie wir sie dazu bringen können, das zu tun, was wir wollen“, sagte Jan Leike, Sicherheitsexperte bei Anthropic.
Quelle: https://znews.vn/nguoi-muon-tao-ra-tieu-chuan-dao-duc-moi-cho-ai-post1541798.html



































































































Kommentar (0)