

في سياق التحول الرقمي والذكاء الاصطناعي في فيتنام، تتزايد أهمية تقنية التعرف الضوئي على الحروف (OCR) في رقمنة المستندات، وأتمتة العمليات التجارية، وتوفير التكاليف، وتحسين كفاءة الإدارة. ومع ذلك، فمع خصائص اللغة الفيتنامية من لهجات وكتابة يدوية، لا تقتصر مشكلة التعرف على الحروف على "قراءة الكلمات"، بل تتطلب من النموذج القدرة على فهم السياق فهمًا شاملًا.
أعلن معهد تطبيق تكنولوجيا CMC (CMC ATI) مؤخرًا عن نموذج CATI-VLM (فهم المستندات المرئية) الذي طوره فريق البحث من مستودع بيانات كبير بسعة 5 تيرابايت، حيث وصل إلى المركز 12 في العالم والمركز الأول في فيتنام في التصنيف الذي أعلنته للتو مسابقة القراءة القوية (RRC) في يونيو 2025 في فئة الإجابة على الأسئلة المرئية للمستندات (DocVQA).
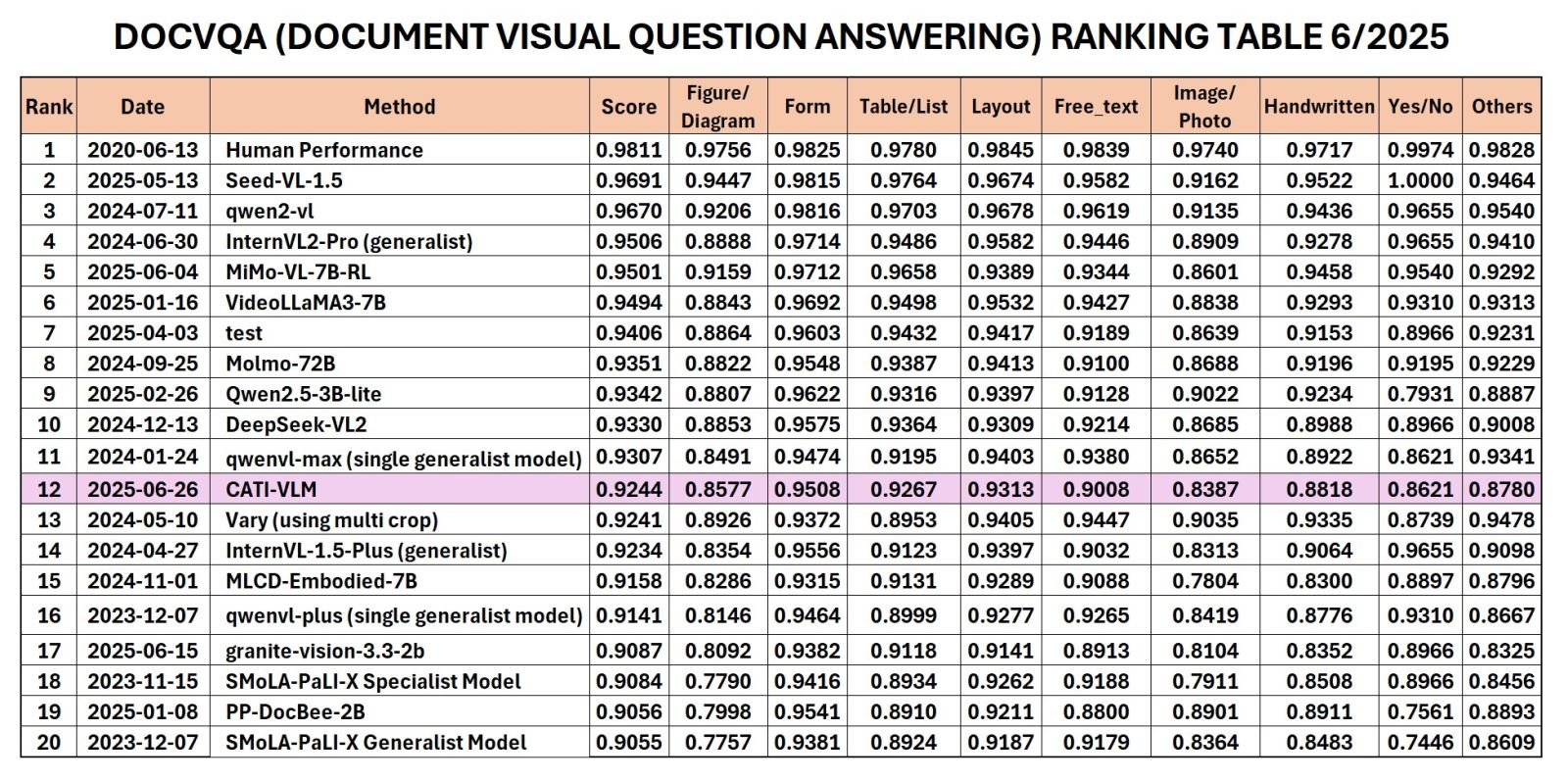
تصنيف RRC في فئة DocVQA 6/2025.
مسابقة القراءة القوية (RRC) هي منصة علمية مرموقة (https://rrc.cvc.uab.es/) ينظمها مركز الرؤية الحاسوبية (CVC) التابع لجامعة برشلونة المستقلة (UAB) بإسبانيا، وهو مركز بحثي مرموق عالميًا في مجال الرؤية الحاسوبية. انطلقت المسابقة عام ٢٠١١، وترافق المؤتمر الدولي لتحليل النصوص والتعرف عليها (ICDAR)، أحد أكبر المنتديات العالمية في تحليل الوثائق والرؤية الحاسوبية، وأصبحت حدثًا مهمًا يجذب الباحثين والمهندسين من جامعات مرموقة ومعاهد بحثية وشركات تقنية مثل جامعة تسينغهوا ومجموعة هيونداي موتور وتينسنت. تهدف مهام مركز القراءة القوية إلى تعزيز التقدم التكنولوجي، وترتبط ارتباطًا وثيقًا بالمشكلات العملية، بدءًا من الترجمة وإدارة بيانات المؤسسات وصولًا إلى تحليل المدن ومعالجة الوثائق التاريخية.
صرح الدكتور دانج مينه توان، مدير مركز CMC ATI، قائلاً: "تتجلى القدرات البحثية لفريق CMC في منصة بحثية عالمية مرموقة مثل مركز RRC. ونحن فخورون بأنه في وقت قصير، تمكن الفريق من تحقيق تصنيف عالٍ، لينافس أسماءً لامعة من الدول المتقدمة. والأهم من ذلك، أن هذا دليل واضح على القدرة على إتقان التكنولوجيا لحل مشاكل فيتنامية محددة ومجالات متخصصة في فيتنام."
يختلف برنامج CATI-VLM عن تقنية التعرف الضوئي على الحروف (OCR) التقليدية، إذ لا يقتصر على استخراج الأحرف فحسب، بل يستوعب أيضًا طبقات متعددة من المعلومات: المحتوى النصي، والعناصر غير النصية (مثل مربعات الاختيار، والمخططات، والتوقيعات، والصيغ)، والتخطيط (هيكل الصفحة، والجداول، والنماذج)، والأسلوب (الخطوط، والإبرازات، إلخ). يستطيع هذا النموذج الإجابة على الأسئلة المرئية المطروحة على صور المستندات، على غرار ChatGPT، دون الحاجة إلى تعلم نماذج محددة مسبقًا.
وفقًا لصحيفة الأخبار والشعب
المصدر: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051








































































































تعليق (0)