

GPU는 AI 컴퓨터의 두뇌입니다
간단히 말해서, 그래픽 처리 장치(GPU)는 AI 컴퓨터의 두뇌 역할을 합니다.
아시다시피, 중앙 처리 장치(CPU)는 컴퓨터의 두뇌입니다. GPU의 장점은 복잡한 계산을 수행할 수 있는 특수 CPU라는 것입니다. 이를 위한 가장 빠른 방법은 여러 GPU를 사용하여 문제를 해결하는 것입니다. 하지만 AI 모델을 학습하는 데는 몇 주 또는 몇 달이 걸릴 수 있습니다. 일단 구축되면 프런트엔드 컴퓨팅 시스템에 배치되고 사용자는 AI 모델에 질문을 던질 수 있는데, 이 과정을 추론이라고 합니다.
여러 개의 GPU를 포함하는 AI 컴퓨터
AI 문제를 해결하는 데 가장 적합한 아키텍처는 랙에 GPU 클러스터를 구성하고 랙 상단의 스위치에 연결하는 것입니다. 여러 개의 GPU 랙을 계층적 네트워크 구조로 연결할 수 있습니다. 문제가 복잡해질수록 GPU 요구 사항이 증가하고, 일부 프로젝트에서는 수천 개의 GPU 클러스터를 구축해야 할 수도 있습니다.
각 AI 클러스터는 작은 네트워크입니다
AI 클러스터를 구축할 때는 GPU가 서로 연결하고 효율적으로 데이터를 공유할 수 있도록 소규모 컴퓨터 네트워크를 설정하는 것이 필요합니다.
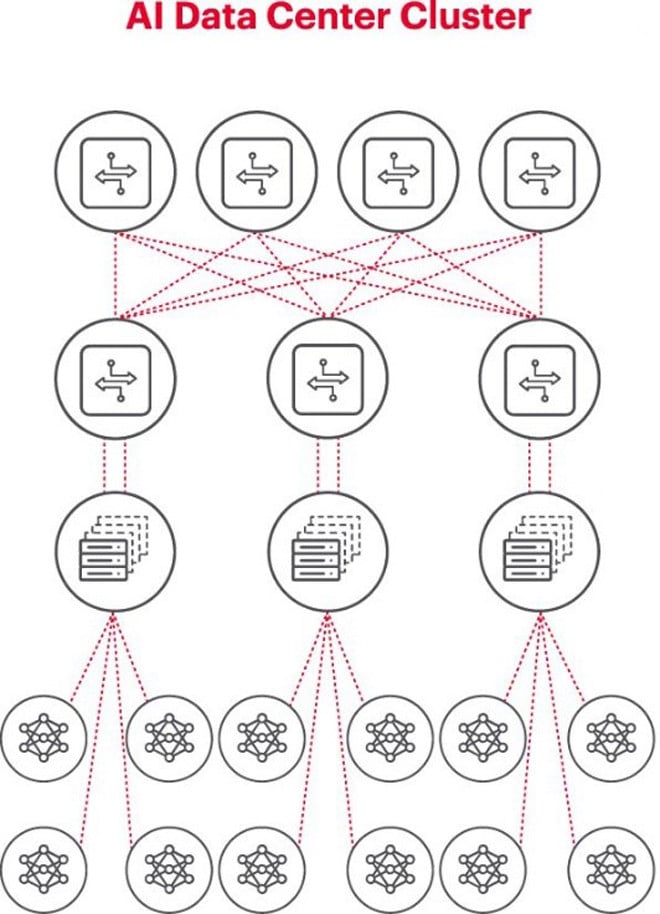
위 그림은 AI 클러스터를 보여주며, 하단의 원은 GPU에서 실행되는 워크플로를 나타냅니다. GPU는 ToR(Top of Rack) 스위치에 연결됩니다. ToR 스위치는 그림 위에 표시된 네트워크 백본 스위치에도 연결되어 여러 GPU가 사용될 때 필요한 명확한 네트워크 계층 구조를 보여줍니다.
네트워크는 AI 배포의 병목 현상입니다.
작년 가을, 대표단이 차세대 AI 인프라를 구축하기 위해 함께 작업했던 OCP(Open Computer Project) 글로벌 서밋에서 Marvell Technology의 대표인 Loi Nguyen은 "네트워킹이 새로운 병목 현상입니다."라는 중요한 점을 지적했습니다.
기술적으로, 네트워크 혼잡으로 인한 높은 패킷 지연 시간이나 패킷 손실은 패킷 재전송을 유발하여 작업 완료 시간(JCT)을 크게 증가시킬 수 있습니다. 결과적으로, 비효율적인 AI 시스템으로 인해 수백만 또는 수천만 달러 상당의 GPU가 낭비되어 기업의 수익과 제품 출시 기간 모두에 손실을 초래합니다.
측정은 AI 네트워크의 성공적인 운영을 위한 핵심 조건입니다.
AI 클러스터를 효과적으로 운영하려면 GPU가 최대한의 성능을 발휘하여 학습 시간을 단축하고 학습 모델을 활용하여 투자 수익률(ROI)을 극대화해야 합니다. 따라서 AI 클러스터의 성능을 테스트하고 평가하는 것이 필수적입니다(그림 2). 하지만 시스템 아키텍처 측면에서 GPU와 네트워크 구조 사이에는 많은 설정과 관계가 존재하며, 이러한 관계들이 문제 해결을 위해 상호 보완되어야 하기 때문에 이 작업은 쉽지 않습니다.
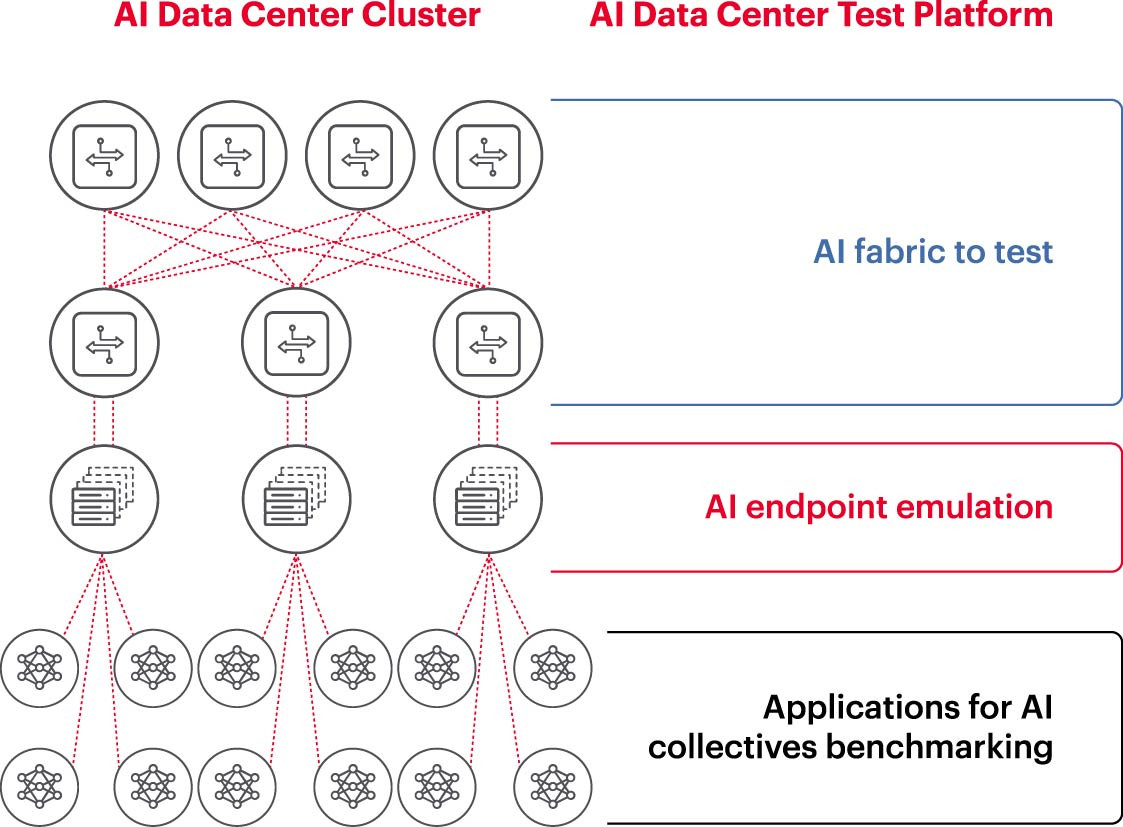
이로 인해 AI 네트워크 측정에 많은 어려움이 발생합니다.
- 비용, 장비, 숙련된 네트워크 AI 엔지니어 부족, 공간, 전력 및 온도의 제약으로 인해 실험실에서 전체 생산 네트워크를 재현하는 데 어려움이 있습니다.
- 생산 시스템에서 측정을 수행하면 생산 시스템 자체의 사용 가능한 처리 용량이 감소합니다.
- 문제의 규모와 범위의 차이로 인해 문제를 정확하게 재현하는 데 어려움이 있습니다.
- GPU가 전체적으로 연결되는 방식의 복잡성.
이러한 과제를 해결하기 위해 기업은 권장 설정의 일부를 랩 환경에서 테스트하여 작업 완료 시간(JCT), AI 팀이 달성할 수 있는 대역폭과 같은 주요 지표를 벤치마킹하고, 이를 스위칭 플랫폼 사용률 및 캐시 사용률과 비교할 수 있습니다. 이러한 벤치마킹은 GPU/처리 워크로드와 네트워크 설계/설정 간의 적절한 균형을 찾는 데 도움이 됩니다. 결과에 만족하면 컴퓨터 설계자와 네트워크 엔지니어는 이러한 설정을 실제 운영 환경에 적용하여 새로운 결과를 측정할 수 있습니다.
기업 연구소, 학술 기관, 대학들은 효과적인 AI 네트워크 구축 및 운영의 모든 측면을 분석하여 대규모 네트워크 운영의 어려움을 해결하고자 노력하고 있으며, 특히 모범 사례가 끊임없이 발전하고 있습니다. 이러한 협력적이고 반복 가능한 접근 방식은 기업이 반복 가능한 측정을 수행하고 AI를 위한 네트워크 최적화의 기반이 되는 "가상(what-if)" 시나리오를 신속하게 테스트할 수 있는 유일한 방법입니다.
(출처: 키사이트 테크놀로지스)
[광고_2]
출처: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html










![[사진] 중앙선전대중동원부, 모범기자단과 만남](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/6/21/9509840458074c03a5831541450d39f8)


























![[해양뉴스] 완하이라인, 1억5천만달러 투자해 컨테이너 4만8천개 구매](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/6/20/c945a62aff624b4bb5c25e67e9bcc1cb)






































댓글 (0)